
Abstract
In this blog post I explore my own data from the online therapy platform Talkspace. I explain how I acquired my data and how others can acquire their own. I describe how I extract some features from my data, and make those features from my own data available via a public API. I plot my data and do a basic regression analysis to test if there is a relationship between the length and complexity of the messages my therapist sends me and the length and response time of my own messages. I find that there is a very weak linear relationship between the length of my therapist's messages and my response time, but this does not affect my velocity (that is, the length of my messages per unit time that I take to respond). This suggests that the messages I am responding to have a limited impact on my own level of activity on the Talkspace platform.
Introduction
What am I trying to understand?
First, some context: About a year and a half ago, I was feeling unwell. I had just graduated college, started my first job, and the gravity of being the custodian of my own life was weighing heavily on me. I had experienced depressive episodes like this before and had sought professional help. Previously, through my university, I started seeing a therapist and started a course of antidepressants which provided some modest benefit. However, after I graduated those university resources went away, and I was now feeling worse than I had ever felt before.
If you're familiar with depression, you know it can be quite difficult to follow through with anything, especially self-care. The process of finding a new therapist and psychiatrist felt insurmountable, but as time went on, my symptoms were getting worse. Eventually, I decided to try something new, so I signed up for online therapy through a service called Talkspace.
I have been using the service for about a year, and over that time, I've seen meaningful improvement to my mood and quality of life (even in the midst of a global pandemic). However, I've noticed it's sometimes hard for me to stay engaged. I've gone through long periods of radio silence with my therapist, and I suspect that that has been an impediment. Patient engagement is critical to developing a therapeutic relationship, so if I can increase my own responsiveness, I might increase the efficacy of my therapy.
That brings me to the first thing I want to understand: How engaged and responsive am I to my therapist?. With my own data, I can gain some insight into how long it takes me to respond, and how long those responses are. Ideally, I could develop a model that could estimate my engagement based on the actual language I send (or don't send), but I don't have any "ground truth" with which to build a supervised model with (and it's unclear to me what an unsupervised version of an engagement model would even look like), so I'll have to use my own naive, intuitive measures of engagement.
Once I have a way of measuring my engagment, I want to answer a deeper question: What explains my responsiveness or engagement with my therapist? If I can find some simple relationship between something I can change and how engaged I am, I have a lever to pull. It would be fabulous to be able to characterize something about my therapist's messages that causes me to engage. That's valuable information not just for me, but for my therapist. Moreso, if I find an effect that generalizes to other people, then I could potentially not only help my therapist's other clients, but an enormous and growing pool of people who use text-based therapy.
The last thing I want to look at is: Can I tell a difference in my messages over time, and what is that difference? If I could build a classifier that could, for example, distinguish before and after I restarted a course of antidepressants (which has helped me tremendously), I might gain some insight into what the internal change was. I don't have access to my historical mood data, but if I did, I would really want to know if I could meaningfully estimate what my PHQ-9 score was on a particular day based on a message. When I asked my therapist what kinds of things he would be interested in investigating, he brought up detecting suicidal ideation. Like the previous question I don't have any ground truth to build a model from, but this question also really interests me.
Getting the Data
How I got, and how you can too
Now that I have a relatively clear picture of the questions I'm trying to answer, I need to actually get my data. Talkspace has no button to download all of your data (To be totally candid, there probably ought to be one, but I dream). Another option is writing a utility that would parse the data from an HTML document. I checked, and it wasn't particularly hard to scroll to the beginning of my message history, and I could write something using Selenium or Detox to automatically scroll to the beginning. However, this approach isn't ideal for two main reasons:
- There is a lot of complexity to take on to write a fragile automated worker to run through the UI and scrape my data for me, and having that features seems crucial for this project to be useful to other people
- The HTML representation does not match up very well with the abstraction I'm trying to work with, which is individual messages with consistent fields like
authororcreated_at.
The HTML has totally distinct concerns from what I'm trying to do
So, abandoning that idea, I think it makes sense to try to call Talkspace's API directly. I can figure out what endpoints to hit by watching what calls the application makes using the network tab in Chrome,
I can see what calls the application makes
The results of trial and error: a successful call to Talkspace
Now that I have that working, I can build a tool that anyone can use to scrape his or her data. That tool is available here and this is what it looks like:

It scrapes all of the messages you've exchanged with your therapist in the form of an array of JSON objects that all share consistent keys such as display_name, created_at, etc. . The tool provides the option to save your data to a local file or to a MongoDB instance.
Now that I have my data, I want to be able to show you, the audience reading this, some of the interesting things I found. However, I obviously don't want to reveal my entire message history with my personal therapist to the open internet. That being said, I am comfortable sharing some information, such as how often I send messages and how long my messages are. With that in mind, I built a public API that takes requests for my scraped messages, extracts relevant features I'm comfortable sharing, and responds with the results in JSON. I'll explain the specific features I'm extracting below, but the API is how I'll access my data here. I'm hosting the API in a serverless framework called Google Cloud Functions. You can view the source code running there at my Github and you can use the API yourself here (results are cached once a day).
Exploring my data
Cleaning and exploring my message history
Now that I have my data, let's explore it. The data I have is in the form of an array of JSON objects, each with identical structures representing one individual "text" exchanged in Talkspace. The messages I scraped include automated messages from the application itself prompting me to fill out forms and questionnaires. Luckily, knowing which texts are sent from a human and which are not is also pertinent to the application, so Talkspace denotes these different modes of message with a field called message_type. This is easily filtered by MongoDB, and immediately eliminates around 10% of the messages I downloaded. Hurray! Smaller problem space!
I'm providing some code samples in Python from the notebook I used to do the original analysis. To see the original Jupyter notebook in Python or R, look here.
RELEVANT_MESSAGE_TYPES = [1]
CONNECTION_STRING =
os.getenv('MONGO_CONNECTION_STRING')
messages = pd.DataFrame([
*MongoClient(CONNECTION_STRING)\
.talkspace\
.messages\
.find(
{
'message_type': {
'$in': RELEVANT_MESSAGE_TYPES
}
}
)
])The next step is to eliminate redundant or uninformative text from the messages I downloaded. It would be basically impossible for eliminate all forms of this, but there are a few obvious patterns I know I want to ignore:
- Talkspace doesn't have a threaded reply feature, so I tend to quote my therapist at the beginning of our messages. Luckily, I always delimit these quotations with a
>. - My therapist consistently greets me with
Vaughn, ..., and signs off withRespectfully, Dallas
I can easily remove these instances with some regex. Because I'm only dealing with a few hundred kilobytes, I even have the convenience of doing it in memory!
ARROW_DELIMITER = re.compile('[^-]> ')
EXTRATA = re.compile(
'(Vaughn,\n*|Respectfully,\n*Dallas)'
)
REPEAT_NEWLINES = re.compile('\n\n+')
def extract_my_words(msg):
if not ARROW_DELIMITER.match(msg):
return msg
return ''.join(
re.split(ARROW_DELIMITER, msg)
)[1:]
def process_message(msg):
msg = extract_my_words(msg)
msg = re.sub(EXTRATA, '', msg)
msg = re.sub(REPEAT_NEWLINES, '\n', msg)
return msg
messages.message = messages.message.apply(
process_message
)
Now that I have some relatively clean text, it's time to consolidate consecutive messages to make analysis simpler. Nearly always, I will respond to my therapist with multiple messages. Each individual message is part of a single response, but in the data I scraped, they appear as individual records. The abstraction I'd like to work with is that each consecutive block of messages from the same person is considered an individual response. I can then redefine some basic aspects of these messages in terms of aggregate functions like concatenation, minimum, etc.
# This is critical for rest of the analysis
messages.sort_values('created_at', axis='rows', inplace=True)
# This associates consecutive messages (in time) from the same person
message_block_index = messages\
.user_id\
.ne(messages.user_id.shift())\
.cumsum()
message_blocks = messages.groupby(message_block_index).agg({
'message': lambda l: '\n'.join(l),
'created_at': min,
'display_name': 'first'
})
Now I can start to come up with some simple features to characterize these messages. The simplest things that immediately come to mind are
- Message Length
- Word count
- Question Count
- Readability
These are all relatively easy to extract
message_blocks['message_length'] =
message_blocks.message.apply(len)
message_blocks['question_count'] =
message_blocks.message.apply(
lambda x: len(re.findall(r'\?', x))
)
message_blocks['word_count'] =
message_blocks.message.apply(
lambda x: len(re.findall(r'\s', x)) + 1
)
message_blocks['readability'] =
message_blocks.message.apply(
textstat.flesch_reading_ease
)
I can also start to think about some measures of my engagement. The thing that come to mind are
- How quickly do I respond to my therapist
- For every day that it takes me to respond, how much am I writing on average?
I can quickly extract those features as well
message_blocks =
pd.concat([message_blocks, message_blocks.shift().add_prefix('prev_')], axis='columns')
message_blocks['response_time'] =
(message_blocks.created_at - message_blocks.prev_created_at) \
/ pd.Timedelta(days=1)
message_blocks['words_per_day'] =
message_blocks['word_count'] / message_blocks['response_time']
Great! Now that I have a handful of features to look at, I can start to make some plots! I'll start by plotting the distributions of the features I just extracted.
These are the distributions of some features that I suspect would affect my responsiveness: readability, message length, word count, and question count
As you can see, the readability scores follow a roughly normal distribution
Question count, message length, and word count all follow a roughly exponential distribution
The features I 'm interested in explaining (response time and word count per day) both show noticeable differences across my therapist's messages and my own. My response times are much more variable, and on average much longer than my therapist's.
Now I 'd like to look at the relationship between current and previous messages. For example, I want to plot the relationship between the readability of a message sent from my therapist and the length of my response. If you have trouble reading this plot, you can see a larger, zoomable version here.
{kind=link}
As you can see from the plots, there is a slight relationship between previous word count and question count, which seems plausible. Other than that, there isn't an obvious relationship anywhere.
Finally, I'd like to look at my messages over time, which should give a sense of how I've used the service over the last year
Long gaps in my use of the service are indicated by larger points. Trends up or down indicate longer messages are being exchanged.
Again, I've provided the R and Python notebooks I originally used to do these analyses. If you'd like to play with the data yourself, or just get a better view of the plots, I'd highly encourage checking them out.
Regression Analysis
Do my therapist's messages affect my engagement?
I want to develop a model that explains my engagement. I think an imperfect but at least obvious and accessible proxy is my responsiveness. I have a simple hypothesis: I tend to be overwhelmed by long messages that are hard to read and contain lots of questions. Specifically, I think I tend to take longer to respond, and have less to say. If I had to take a guess, I would assume that these would have a roughly linear relationship. That is, I imagine for every additional question my therapist asks me, I take some additional unit time to respond. With that kind of model, linear regression seems like an obvious choice to test my hypothesis.
To be clear, this data is not perfectly suited for linear regression. The response variables I'm interested in does not appear to be normally distributed with any of its covariates, and the covariants aren't perfectly non-collinear. The observations are obviously not independent (though my response time, message length, and message length over response time don't seem to show any obvious autocorrelation). However, I think it's still worth taking a look.
The way I see it, I think I have three explanatory variables and three response variables. My response variables are
- Response time
- Message length
- Message length per unit response time
- Previous message readability
- Previous message length
- Previous message question count
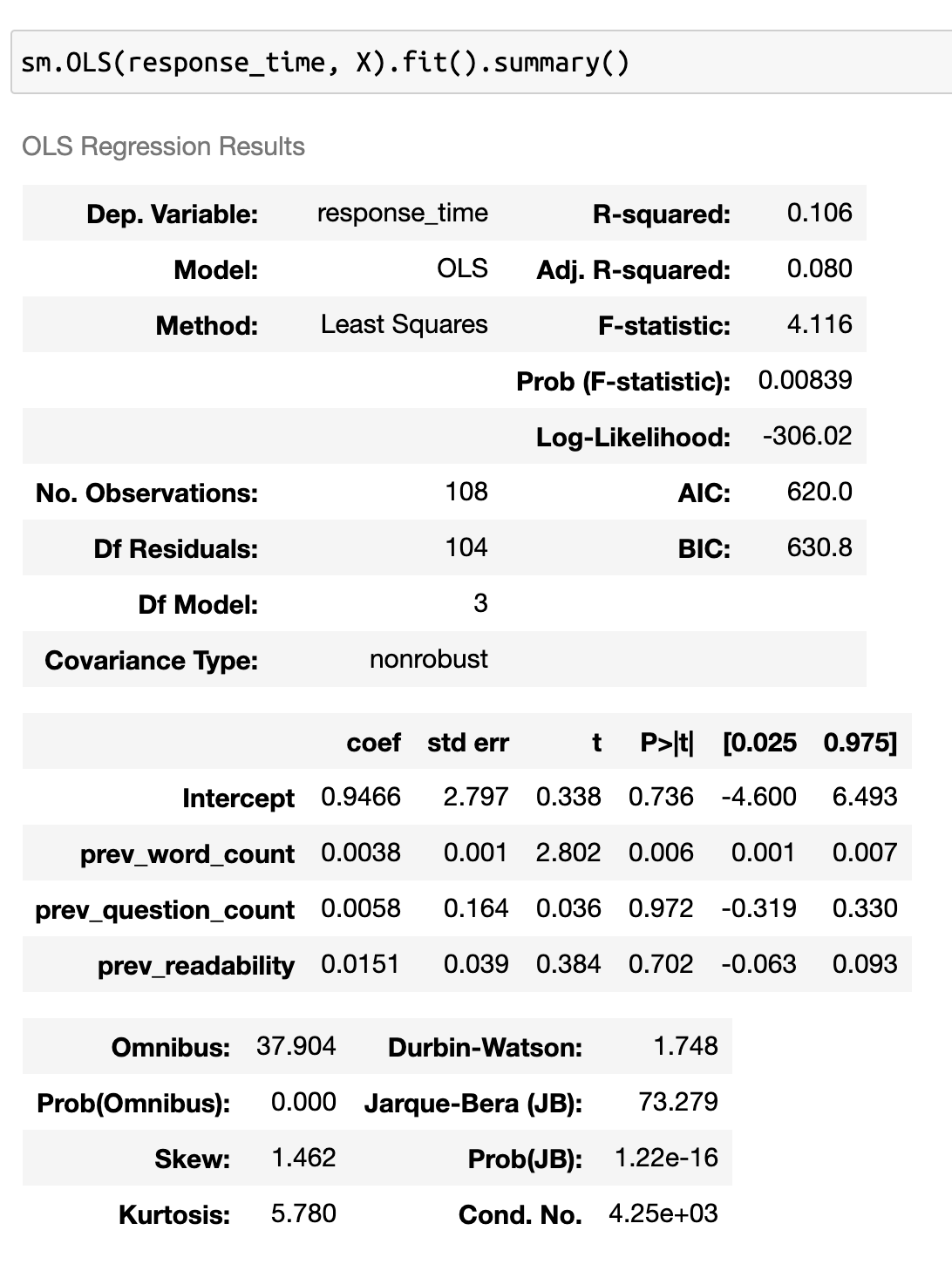
At this point, it's fairly easy to set up three regressions for my three response variables. Let's first look at message length. I'll fit a model, look at some results and some diagnostic plots.
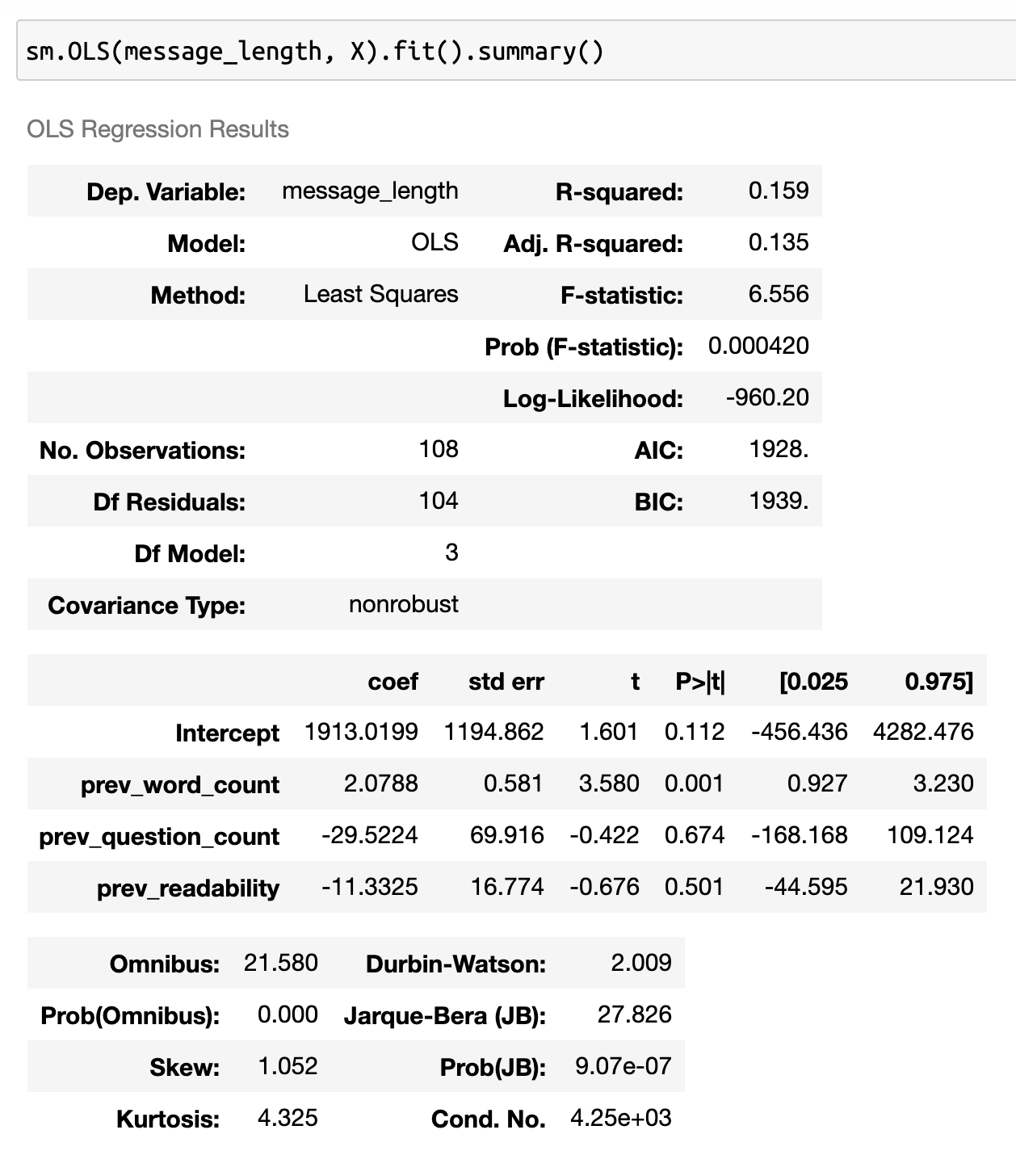
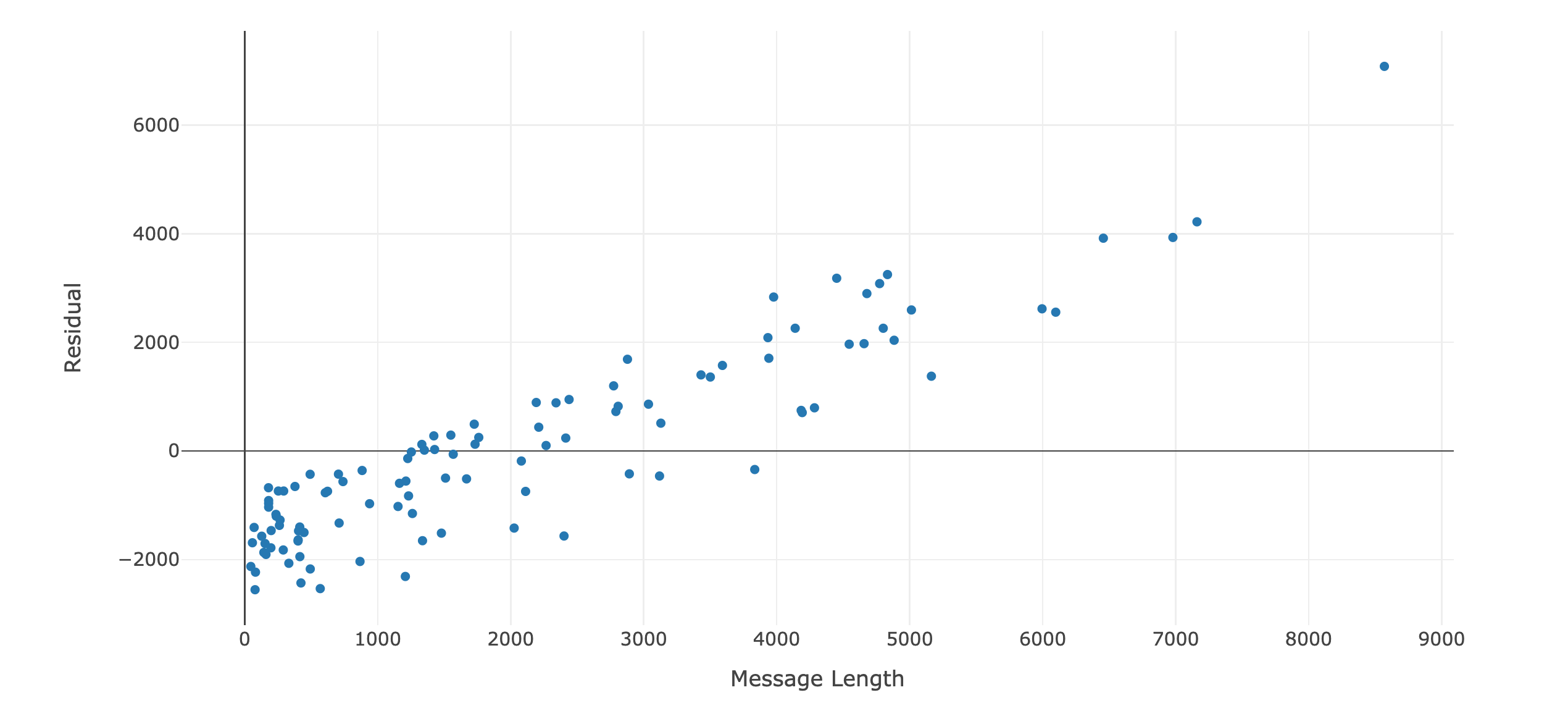
The first thing I notice from these results is that this model is not a very good fit. The R2 is very low. Sure, I have some significant results, but statistical significance is a test of sample size, not whether my model is appropriate. Looking to a plot of the residuals is a clear indication the relationship between my features and response is non-linear
Looking at the outcomes of response time and message length over response time produce similarly poor fits with clearly patterned residual plots
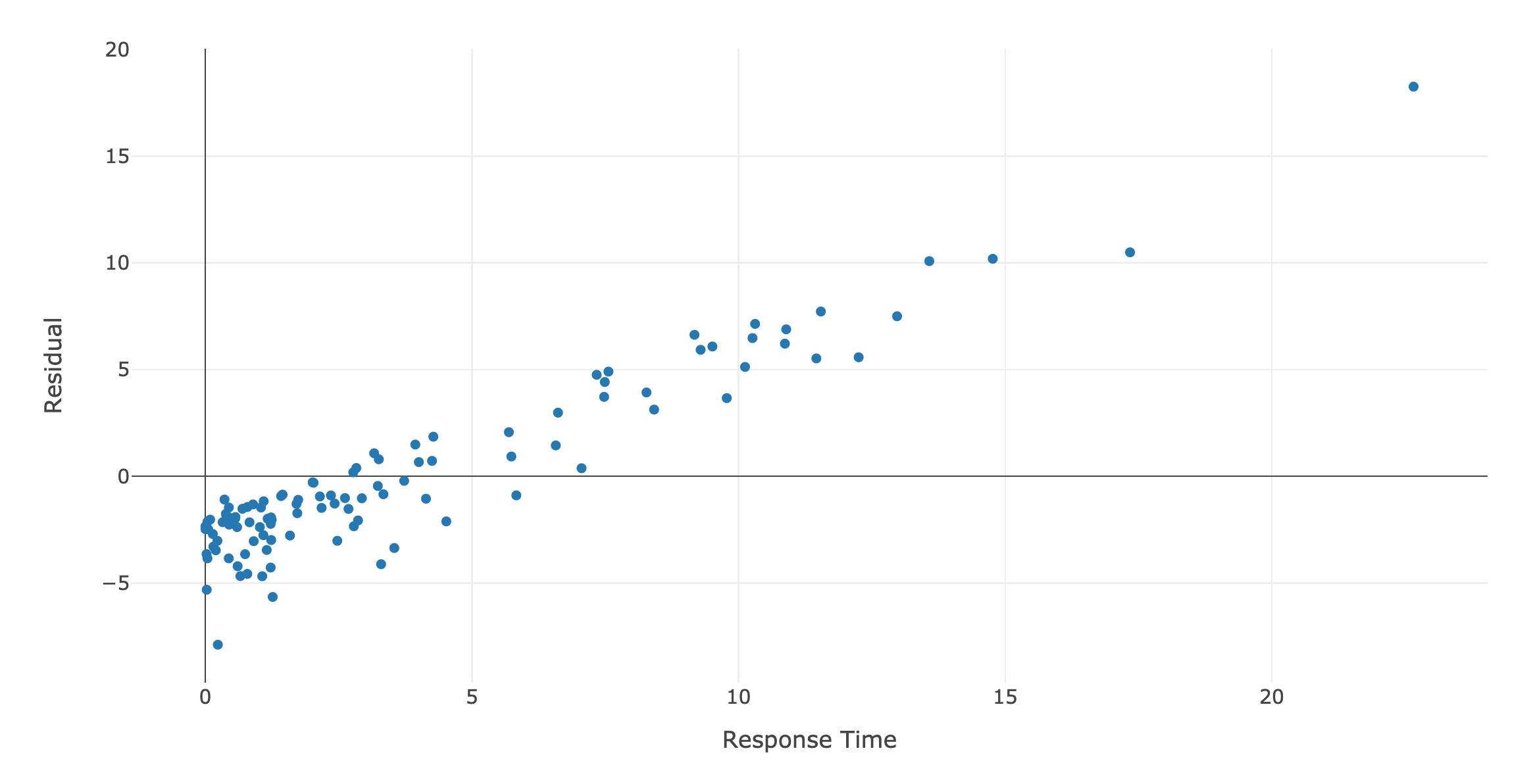
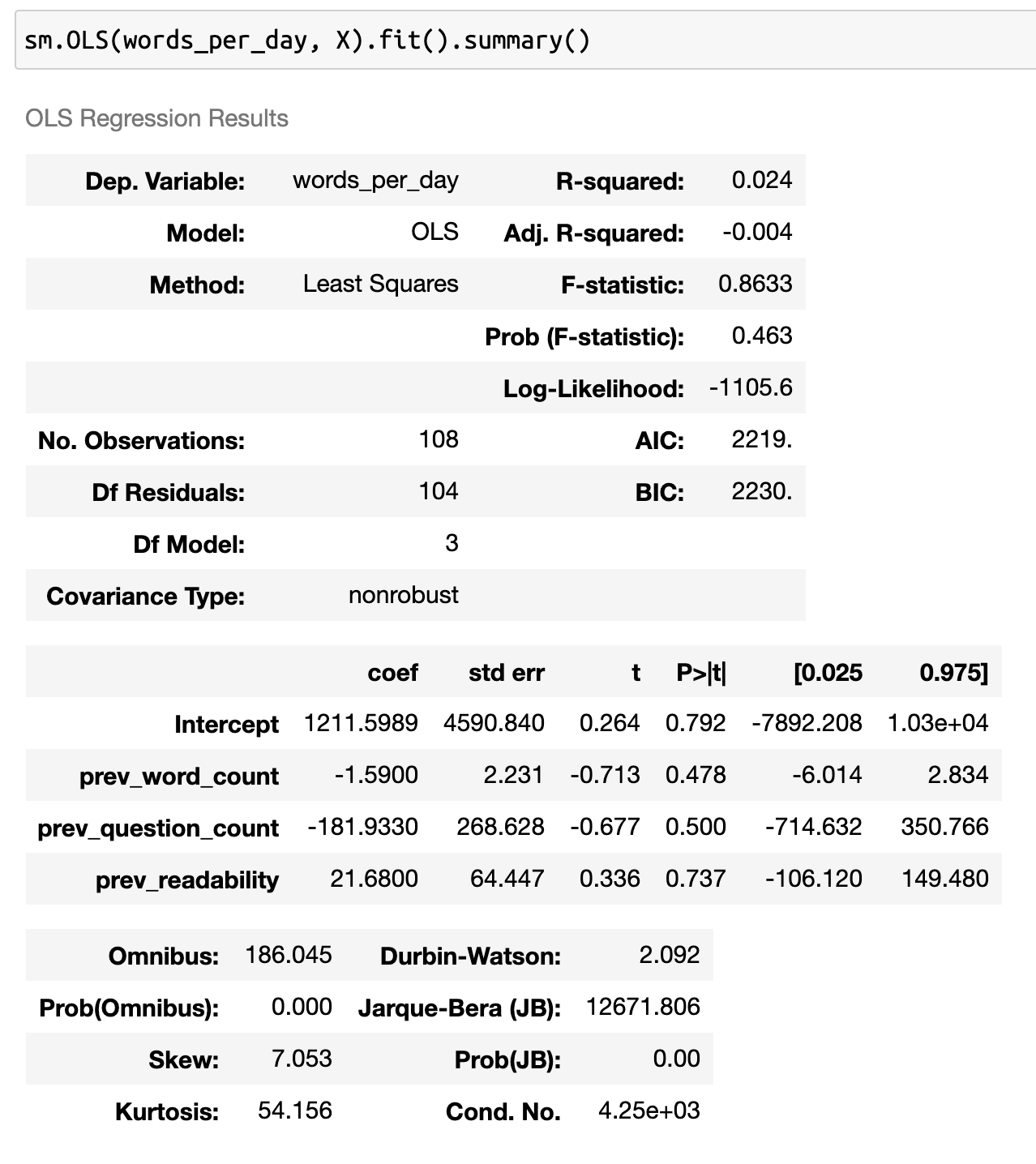
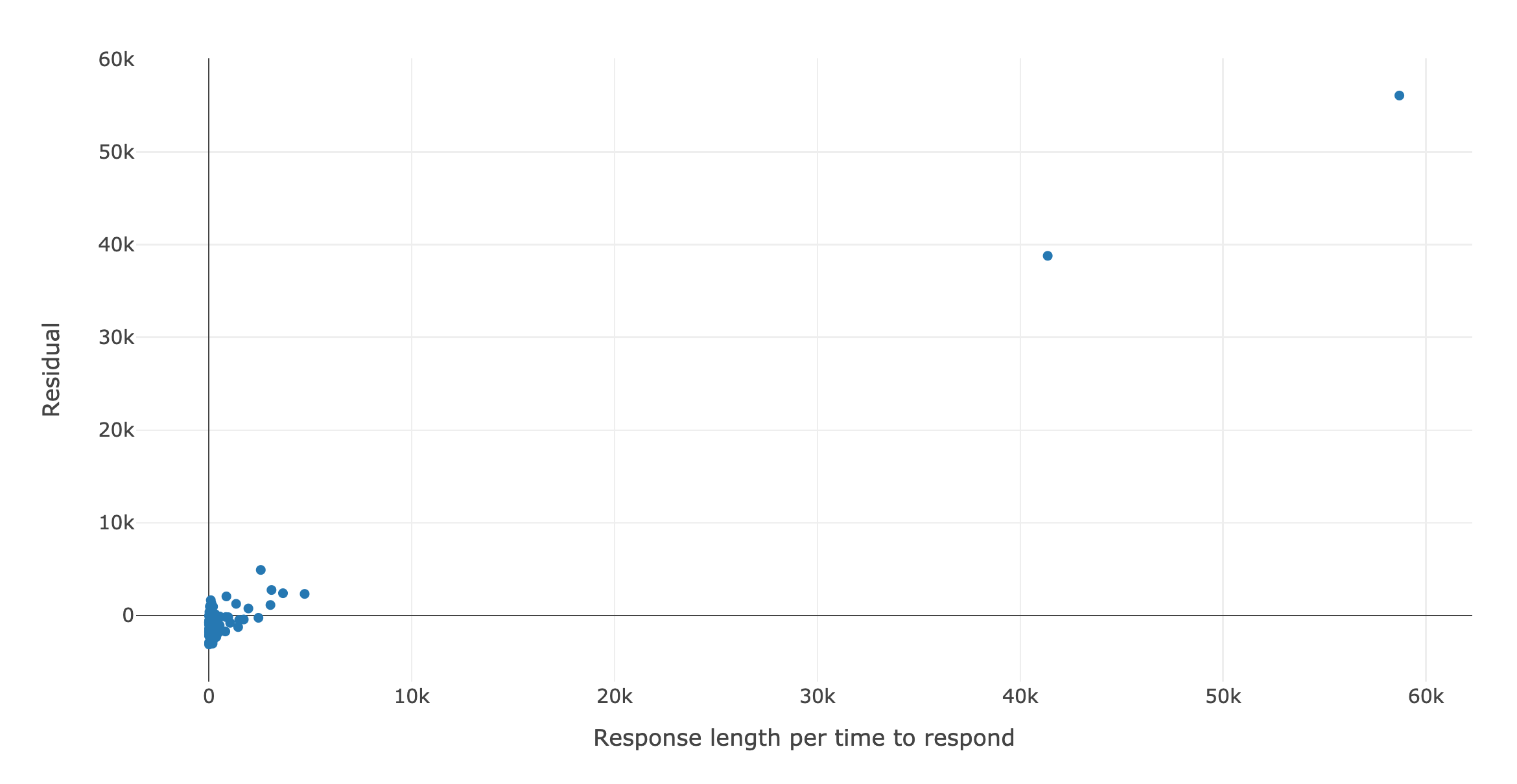
While these results aren't particularly spectacular, they're still informative. We can say pretty confidently that there isn't an obvious linear relationship between any of the measurements of engagment I have and the messages from my therapist. It also gives great indications for areas to look at next. For both response time and message length, there is a statistically significant relationship with the length of my therapist's messages, but that relationship doesn't show up when I regress on the ratio of those two values. While the effect isn't very strong, and certainly isn't linear, there's definitley something there. This is probably an indication that my response times and message lengths are positively correlated, which is why their ratio doesn't have any significant covariates.
Conclusion
Takeaways and next steps
The biggest takeaway I got from this analysis was that my therapist can be fairly assured that my responsiveness is not a function of his messages' sentence structure, length, or how many questions he's addressing to me. I also took away that the "velocity" of my message writing seems to vary a lot. If you look at the residuals plot for message length over response time, you can clearly see two outliers. I looked up both of those messages, and the content and context of those messages wasn't particularly special or interesting. This indicates to me that whatever mechanism there is that causes me to sometimes reduce my engagement with Talkspace, it's more complicated and nuanced than the factors I looked at here.
With that being said, the next thing I'd like to do is build a language model to actually consider the linguistic content of my data. Even something as simple as TF-IDF could help pick up on signals that might be missed by my therapist. I'd also like to integrate some other sources of data on myself that I have, including running and nutrition.